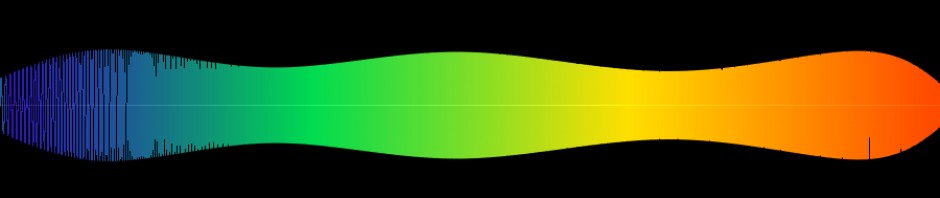
Last week I decided that for nightingale we need a new wav2png, and preferably one written in python, using the awesome python image library. After talking a bit to Ricard it was clear that using numpy and audiolab it would be a piece of cake. Well, a big piece of cake, but still. Once I got going, I went a bit overboard and decided that it would be nice to have a spectrogram of the sound as well, perhaps displayed when you move the mouse over the large image in the sound page.
It took me about 2 and a half days of coding and testing to make it robust (it needs to work for 5-sample wave files and 5-million-samples wave files) and looking good. Some sensible feedback from the guys at oneDot.only made me decide that we had to cut back on the number of colors in the waveform view. The current one looks really ugly in my opinion, so… that was changes as well. It’ll take a while for people to become accustomed to the new colors, but it makes sense to me. I threw in some vertical anti-aliasing for that extra slick look.
For those who don’t know what a spectrogram is, have a look at the wikipedia entry for it.
Without further ado, I present you some results. First of all my own “test” file, a sinusoid sweep:

and its spectrogram:

An FM percussion loop from walkerbelm:

and its spectrogram:

A bell sequence from ERH:

and its spectrogram:

You can find the full source code to generate these images in the nightingale repository ( http://github.com/bram/freesound/tree/master ), in particular look in the directory /freesound/utils/audioprocessing/
You’ll need to install python, numpy, PIL and audiolab to make it work. See above for the links.
Let me know what you think!
I followed your link to Wikipedia and ended up at a link for the short time fourier transform.
http://en.wikipedia.org/wiki/Short-time_Fourier_transform
There was an image there that I liked better than the spectograms you showed, though it has the same information. It is probably more compute intense though.
http://en.wikipedia.org/wiki/Image:Short_time_fourier_transform.PNG
I find the existing thumbnails just fine, though the new ones are slicker. The idea of being able to get a gestalt of a sound at a glance is excellent.
In response to wisslegisse:
Although the 3D images are cool looking, I find the 2D spectrogram much easier to read.
Nice work!
Thanks for this!
I’ve been playing with some scripts but the fastest one took at least 50 seconds per file (one minute). This one just takes 5 seconds!
A question: from what I understand, this script assumes that the wav is a mono 44.1kHz?
ljvillanueva: as far as I know, it should work just fine with other sampling rates. The waveform display: definitely. The spectral view, that might fail, it hasn’t been tested. Experiment, and let me know, I’d say…
Why re-invent the wheel ?
See http://www.linuxbandwagon.com/image2wav/ for a python script (use http://psyco.sourceforge.net/ to make it run faster)
The BEST pictures come from The_vOICe http://www.seeingwithsound.com/javoice.htm if you are willing to run a Java Applet instead of using Python … This page shows a low-res view but you can adjust the parameters so it looks like the new picture at the bottom of http://en.wikipedia.org/wiki/Spectrogram
SumGuy: those programs do the inverse (convert sound into image). wav2png does the inverse: it plots a sound.
Psyco doesn’t speed up wav2png: as it already uses numy, it’s pretty hard to make it faster.
The author of image2wav could do the same (use numpy for his FFT) and would get the results a LOT faster.
To follow up my previous comment, it assumes the wav has a sample rate of 44.1 kHz, otherwise the scale is wrong. I made some changes to get the scale in arithmetic (vs log) scale and to select the maximum frequency to draw. I’ve posted the script in my wiki.
i think it’s awesome !
wouldn’t you be able to make some simple apps for those who aren’t programmers ?
I get a strange error running this.
[root@server ~]# ./wav2png.py
File “./wav2png.py”, line 54
will_read = num_frames_left if num_frames_left < frames_to_read else frames_to_read
^
SyntaxError: invalid syntax
This is on a CentOS 5.1 x64 box, python 2.4.3 default RPM installed. Any ideas?
Edit to above: the ^ chatacter is right below “if” in the “_left if num_frames……” line.
the ternary expression is a feature of python 2.5… you’ve got 2.4.3 installed. Just rewrite the ternary expression:
a = A if C else B
is the same as:
if C:
a = A
else:
a = B
Pingback: Freesound.org - Creative Commons
I found the code very helpful for a project where I needed some basic sound analysis, thanks alot.
Hi
The SVN URL doesn’t work any more since you have moved to git. I couldn’t find the latest version of wav2png in the git repository – is there any chance you could send me a link to it?
Thanks,
Mark
Mark, please see http://github.com/bram/freesound/tree/master
In particular: http://github.com/bram/freesound/tree/c71aa75126c06d87651c833b134dd2f7f4b2f137/freesound/utils/audioprocessing
This also depends on django and for me it MUST be launched with an uneven height (eg -h 257, NOT -h 256). Otherwise I get errors.
Unexperienced people like me should get audiolab from here: http://pypi.python.org/pypi/scikits.audiolab
The django dependencies can be removed quite easily as far as I know…
Let me know what kind of errors you get with even height!
actually, I just checked, are you sure you used the LATEST version, and not the checkin I was referring to in the last post? Go here: http://github.com/bram/freesound/tree/master and then browse to freesound > utils > audio processing, or alternatively, just use git to clone the repositlry!
Yes, I just realised that I won’t need django (commented out “from django.utils import simplejson” in processing.py). 🙂
The error is
==================
$ python wav2png.py somefile.wav
processing file somefile.wav:
Traceback (most recent call last):
File “wav2png.py”, line 46, in
create_wave_images(*args)
File “/home/hannes/ramdisk/freesound/utils/audioprocessing/processing.py”, line 440, in create_wave_images
waveform = WaveformImage(image_width, image_height)
File “/home/hannes/ramdisk/freesound/utils/audioprocessing/processing.py”, line 280, in __init__
raise AudioProcessingException, “wavefile images look much better at uneven height”
processing.AudioProcessingException: wavefile images look much better at uneven height
==========================
It’s the AudioProcessingException bit it does not like. If I replace it with a ‘print “error”‘ it works fine.
I am using Python 2.6 (I think), maybe that’s the culprit. It’s not like I know Python at all. 🙂
I am definitely using the latest version (grabbed a .tar.gz off GitHub).
Wonderful script. Thank you!
Ah, my bad, this error is raised by myself, as (as the error says) “wavefile images look much better at uneven height”! You only need the simplejson if you’re doing other things, like getting audio file information via those functions…
If you make any changes to the script, or use it somewhere public, please let me know!
Heh, well there you caught an amateur. I overlooked the “Exception” bit and thought it was supposed to simply print it as a warning. Thanks.
So far I made it convert any files I throw at it to WAV (in a ramdisk and yes, at the moment it would convert WAV to WAV…) and only output the waveform. That’s pretty ok for my copy’n’paste’n’fix approach.
This is so great to quickly scan an album for its loudness/dynamics.
Is the scale of the waveform graph always the same?
My goal would be to make it render clipping red (like Audacity can do). But if I will ever manage to do is questionable. Well, it’s for fun only.
I have searching the net for ages now trying to find some kind of script that I can run on a website that will scan uploaded files and create a waveform that can be used by a flash player.
can this be used in a php environment?
for an example, just listen to any track on http://www.djdownload.com and tehn check out the player.
looks great by the way!
Brad
If you have Python on your server and can install some additional modules this should work fine…
thank you for sharing this!
Hi,
Are all the files in the audioprocessing dir (http://github.com/bram/freesound/blob/master/freesound/utils/audioprocessing/) required to make this work?
I am getting this error:
Traceback (most recent call last):
File “wav2png.py”, line 4, in ?
from processing import create_wave_images, AudioProcessingException
File “/tmp/processing.py”, line 55
will_read = num_frames_left if num_frames_left < frames_to_read else frames_to_read
^
SyntaxError: invalid syntax
If you are getting that error, it most likely is because you are using an older version (2.3/2.4) of python. Try updating to 2.6…
Thanks Bdejong for you prompt reply.
I got python 2.6 installed, reinstalled PIL, Audiolab and Numpy because they didnt work anymore..
Now stuck on this error:
python wav2png.py input.wav
Traceback (most recent call last):
File “wav2png.py”, line 4, in
from processing import create_wave_images, AudioProcessingException
File “/tmp/processing.py”, line 29, in
import scikits.audiolab as audiolab
File “/usr/local/lib/python2.6/site-packages/scikits.audiolab-0.10.2-py2.6-linux-i686.egg/scikits/audiolab/__init__.py”, line 25, in
from pysndfile import formatinfo, sndfile
File “/usr/local/lib/python2.6/site-packages/scikits.audiolab-0.10.2-py2.6-linux-i686.egg/scikits/audiolab/pysndfile/__init__.py”, line 1, in
from _sndfile import Sndfile, Format, available_file_formats, available_encodings
ImportError: libsndfile.so.1: cannot open shared object file: No such file or directory
I installed libsndfile from source. No go.
Your help would be appreciated.
Hi, I got it solved by:
export LD_LIBRARY_PATH=/usr/local/lib/
Converted to work as a Gnome thumbnailer: http://flic.kr/p/7QJpid
Endolith, that is VERY cool 🙂 Also an interesting idea, the one about mixing up the color as a true color spectrum. Let me know if/when you give it a shot!
Don’t like the short-sound-means-crash, I thought I had tested it out on super short samples… If you find the problem let me know so I can patch up my version.
– Bram
Got an error about alsa:
/usr/local/lib/python2.6/dist-packages/scikits.audiolab-0.10.2-py2.6-linux-x86_64.egg/scikits/audiolab/soundio/play.py:48: UserWarning: Could not import alsa backend; most probably, you did not have alsa headers when building audiolab
warnings.warn(“Could not import alsa backend; most probably, ”
processing file /voice.wav:
Traceback (most recent call last):
File “/usr/local/bin/wav2png/wav2png.py”, line 40, in
create_wave_images(*args)
File “/usr/local/bin/wav2png/processing.py”, line 448, in create_wave_images
waveform = WaveformImage(image_width, image_height)
File “/usr/local/bin/wav2png/processing.py”, line 288, in __init__
raise AudioProcessingException, “wavefile images look much better at uneven height”
processing.AudioProcessingException: wavefile images look much better at uneven height
Went back and did apt-get install alsa, then redid the audiolab install, but still get the error, any ideas?
I run an internet radio station and I make podcasts available each week. I’d love to turn the podcasts into a graphical waveform to sit in a player – much like what is featured on Soundcloud. Is this possible using the technique above to do this? And could it be run as a script – like a cron job to process files either at the time of upload or batch processed at regular intervals?
Thanks,
Rich
hi,
I had a tough time installing this one, stuck with this one error which i cant find much on google about;
IOError: encoder zip not available
I have python 2.7 with zlib, jpeg and freetype installed on the server. When building PIL it shows support for all three above. However i notice at
ImageFile._save(im, _idat(fp, chunk), [(“zip”, (0,0)+im.size, 0, rawmode)])
Complete error dump::
processing file M1F1-Alaw-AFsp.wav:
0% 10% 20% 30% 40% 50% 60% 70% 80% 90% 100% Traceback (most recent call last):
File “wav2png.py”, line 45, in
create_wave_images(*args)
File “/root/a/freesound/freesound/utils/audioprocessing/processing.py”, line 479, in create_wave_images
waveform.save(output_filename_w)
File “/root/a/freesound/freesound/utils/audioprocessing/processing.py”, line 391, in save
self.image.save(filename)
File “/usr/local/lib/python2.7/site-packages/PIL/Image.py”, line 1439, in save
save_handler(self, fp, filename)
File “/usr/local/lib/python2.7/site-packages/PIL/PngImagePlugin.py”, line 572, in _save
ImageFile._save(im, _idat(fp, chunk), [(“zip”, (0,0)+im.size, 0, rawmode)])
File “/usr/local/lib/python2.7/site-packages/PIL/ImageFile.py”, line 481, in _save
e = Image._getencoder(im.mode, e, a, im.encoderconfig)
File “/usr/local/lib/python2.7/site-packages/PIL/Image.py”, line 401, in _getencoder
raise IOError(“encoder %s not available” % encoder_name)
IOError: encoder zip not available
Please do advise!
Mike D: use uneven height, read the error messages
Dhruv: sorry, that’s a PIL error, can’t help you with that
Hi,
I am using this tool for the generation of png wave form of wav file. But thing is … it work only for M1F1-Alaw-AFsp.wav but the wav file I am getting from the mp3 file by the conversion using “lame” command does not go with the wav2png.py properly. The file “processing.py” can not able to read the generated wav file at all. Below you can find the error dump :
[server upload_file]# lame example/uploads/4_239.mp3 example/uploads/4_239.wav
ID3v2 found. Be aware that the ID3 tag is currently lost when transcoding.
LAME 3.98.2 64bits (http://www.mp3dev.org/)
Using polyphase lowpass filter, transition band: 16538 Hz – 17071 Hz
Encoding example/uploads/4_239.mp3 to example/uploads/4_239.wav
Encoding as 44.1 kHz j-stereo MPEG-1 Layer III (11x) 128 kbps qval=3
Frame | CPU time/estim | REAL time/estim | play/CPU | ETA
2910/2910 (100%)| 0:05/ 0:05| 0:05/ 0:05| 14.647x| 0:00
—————————————————————————————————————————-
kbps LR MS % long switch short %
128.0 30.1 69.9 99.8 0.1 0.1
Writing LAME Tag…done
ReplayGain: +1.4dB
[server upload_file]# lame V2 example/uploads/4_239.mp3 example/uploads/4_239.wav
lame: excess arg example/uploads/4_239.wav
[root@acroplia-1 upload_file]# python wav2png.py -a ./wave_images/4_241.png -h 31 -w 100 4_241.wav
processing file 4_241.wav:
Traceback (most recent call last):
File “wav2png.py”, line 45, in
create_wave_images(*args)
File “/opt/lampp/htdocs/upload_file/processing.py”, line 456, in create_wave_images
processor = AudioProcessor(input_filename, fft_size, numpy.hanning)
File “/opt/lampp/htdocs/upload_file/processing.py”, line 96, in __init__
max_level = get_max_level(input_filename)
File “/opt/lampp/htdocs/upload_file/processing.py”, line 66, in get_max_level
audio_file = audiolab.Sndfile(filename, ‘r’)
File “_sndfile.pyx”, line 488, in scikits.audiolab.pysndfile._sndfile.Sndfile.__init__ (scikits/audiolab/pysndfile/_sndfile.c:4251)
IOError: error while opening 4_241.wav
->error while opening file 4_241.wav
-> System error : No such file or directory.
please advise at your earliest.
Supriyo, it’s quite clear: lame is not generating the output file, the file doesn’t exist… Please try to fix your own errors first.
Pingback: j0wn music | kmos-dev
If anyone needs con generate waveform images like the one on soundcloud, I’d recommend to check out https://github.com/beschulz/wav2png/ . It’s written in C++, and build and runs in Linux and Mac OS X (command line and GUI). It natively reads wav, ogg and everthing libsndfile does. If you need to convert mp3s or other formats, you can easily pipe the output from ffmpeg or sox into it.
Hope, that it will be of use to anyone.
Cheers
— Benjamin