The Universitat Pompeu Fabra (of which the Phonos Foundation and Freesound are part of) has published a comprehensive article titled 20 years of sound sharing at Freesound, the prominent international project founded at the UPF. The article traces the 20-year journey of Freesound, explaining how the project emerged to give researchers and creators free access to sound recordings, then evolved from a simple database into a sophisticated platform with tools, APIs, datasets, and technologies for sound analysis. The article also highlights Freesound’s impact on creativity, as well as its role in community-based research, sound culture initiatives, and citizen participation projects. Finally, it examines how Freesound has become a valuable resource for artificial intelligence research, while discussing current efforts to ensure that AI serves the interests of the community.
The Freesound 20th Anniversary Composition Contest was launched on February 2025, by Fundació Phonos and the Freesound team. For the record, terms for participation are available here. The contest invited sound artists, composers, and explorers from around the world to create works around the theme of Intangible Heritage, using only sounds from the Freesound archive.
Intangible Heritage includes the intangible and ephemeral elements that shape our world – whether rooted in human culture, natural environments, or the entangled interplay between them. These sounds reflect what is fragile, ever-changing, and at risk of disappearing. Freesound, with its extensive archive, provides a digital space where these sounds can be preserved and reimagined.
A total of 42 works were submitted to the contest, with the winners being announced in the Freesound blog. A live event took place during the Freesound Day on October 28th, 2025, in which a listening session of a selection of contest submissions was carried out. The present collection features the contest submissions created by various artists who gave us permission to share their works online. This includes a total of 26 pieces. If you submitted a piece to the contest and you want it to be part of the release, please let us know and we’ll add it 🙂 Information about every individual composition is available when provided by the authors, together with a list of Freesound sounds used for the composition.
It looks like 2025 is already over, and many things have happened this year. We celebrated the 20th anniversary of Freesound with a composition contest, a sound installation, and the Freesound Day, which featured talks from people from the Freesound community (the video recordings of the Freesound Day talks are already available!). In the midst of our celebration hangover, it is now time to compute some statistics to summarise 2025 in numbers. The post starts with some numbers and figures following the same post structure that we use every year, and ends with a section in which we analyse the types of sounds uploaded to Freesound using our new Broad Sound Taxonomy (which was introduced in 2025). Without further ado, the number of new sounds uploaded during 2025 has been of…
47,068 new sounds!
which corresponds to…
1494 hours of audio!
In terms of number of sounds, this is 9k less sounds compared to 2024, but in terms of duration, this is ~340 more hours. In fact, the average sound duration is significantly higher in 2025: 114 seconds (compared to 73 in 2024 and 101 in 2023). As usual, these statistics can vary from one year to the next and it does not necessarily mean that there’s a relevant pattern. The influence of individual users is easily significant on a site the size of Freesound.
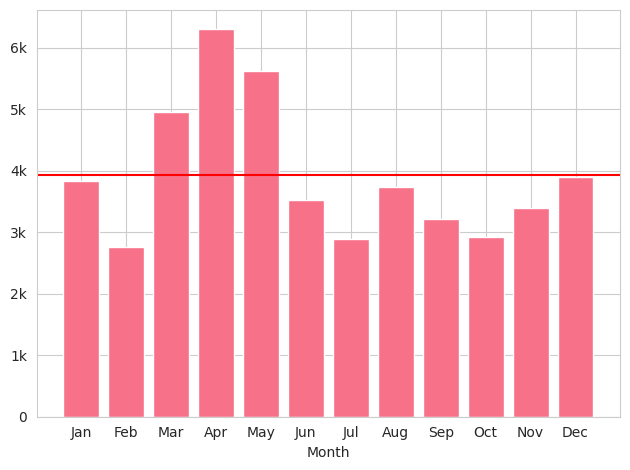
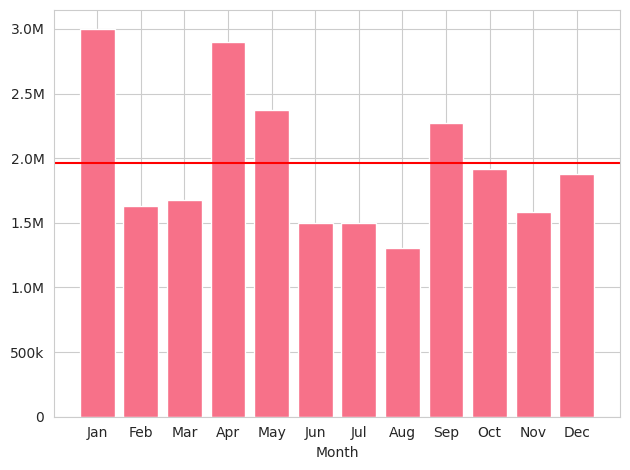
As a new addition to the “Freesound in numbers” usual stats, here you can see the number of sounds uploaded per month (and the average as a red line). It looks like northern hemisphere spring months are those with more upload activity.
Number of sounds uploaded per month in 2025
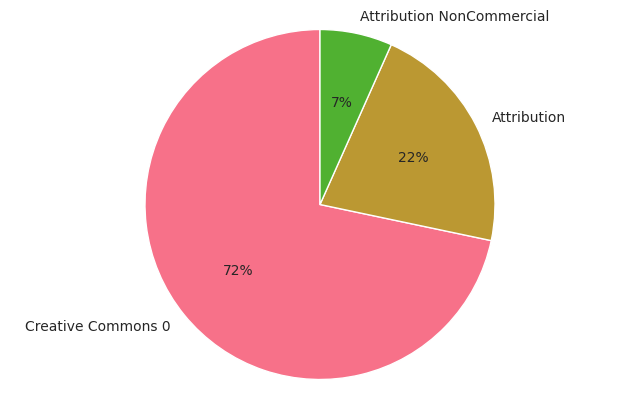
Let’s continue looking at the licenses of uploaded sounds. Here is the Creative Commons license distribution of the newly uploaded sounds:
Distribution of licenses for the sounds uploaded in 2025
It is interesting to see how Creative Commons 0 (CC0) peaks at 72%, and Attribution NonCommercial reaches a historic minimum. Last year we observed significant decrease in CC0 licenses sounds, and we hypothesised that could be due to concerns about generative AI model training. Nevertheless, the tendency does not seem to be continuing this year, on the contrary, there have been more CC0-licenses sounds than ever.
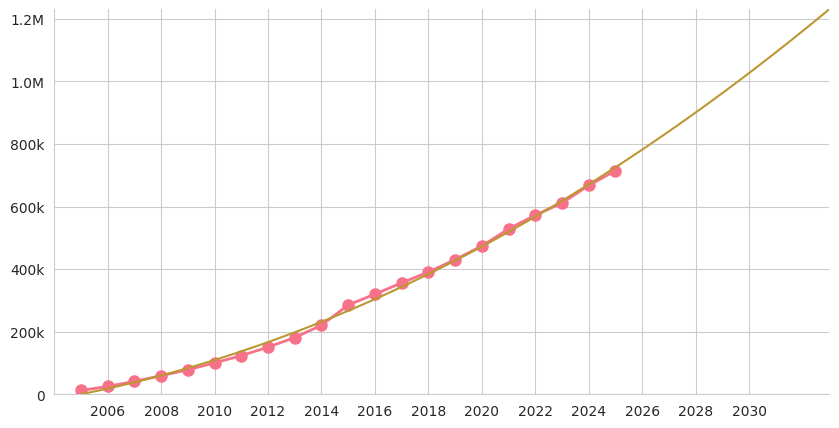
With the new additions from 2025, Freesound now currently hosts a stunning total of 714,671 sounds (YES, we surpassed the 700k mark!). The total audio duration is of 536 days and 8 hours. Here is the evolution of the total number of sounds since the beginning of Freesound, and the prediction for the future:
Total number of uploaded sounds and prediction for the future
Maybe we can get to 1M by the 25th anniversary of Freesound in 2030? Hmmmm, we’ll probably be quite close anyway!
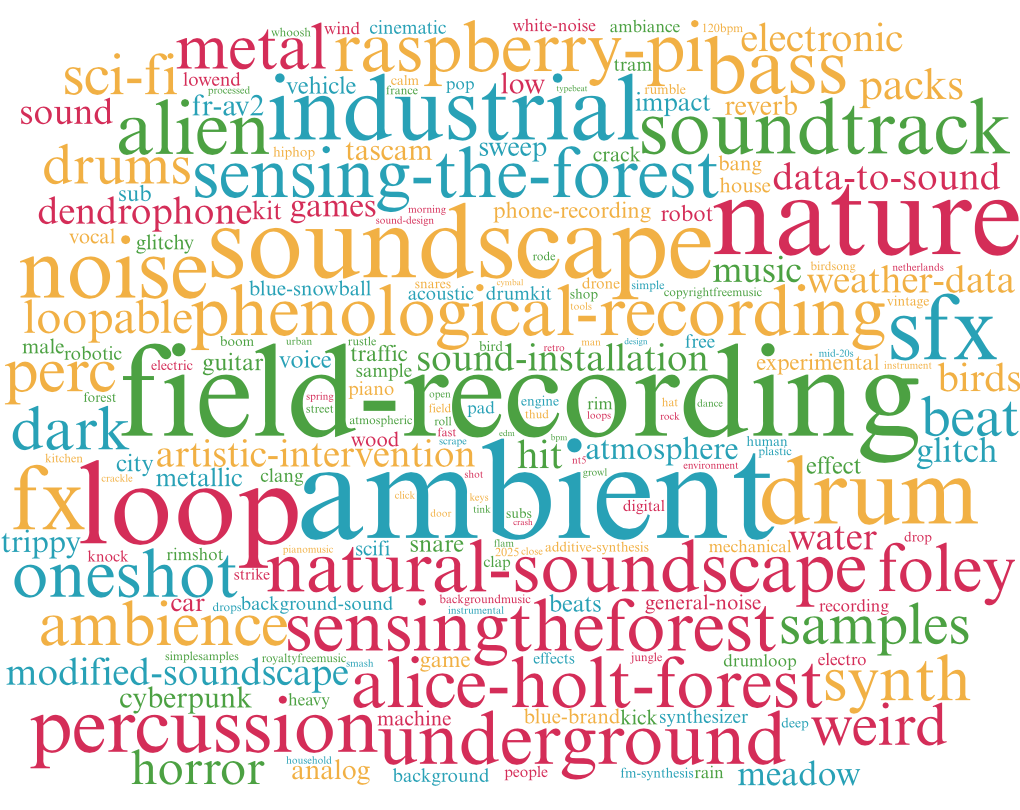
Here is a tag cloud of the tags of the sounds uploaded during 2025:
“Tag cloud” of the most used tags in 2025 NOTE: to improve clarity a bit, this image was updated with respect to the original one published in the post
Just like every year, we can see some of the classic tags again in the cloud. It is hard to draw strong conclusions just by looking at the picture, but if you look at it closely maybe you’ll find curious tags and some inspiration. The characterisation of the types of sounds uploaded deserves further research so we can have better guesses about any possible existing patterns. Maybe using the Broad Sound Taxonomy could be a good ideafor this right? Well, at the end of the post you might find some stats about that 🙂
And now the moment many of you are waiting for: the chart of most prolific sound contributors! You know what? Let’s first pause for a second and listen to some of the best-rated/most-downloaded sounds of 2025:
After this nice intermission, let’s delay it no further: here is the chart of users who have contributed the most sounds in 2025:
Let us take this opportunity to thank all sound contributors (not only those appearing in the table)! It is incredible to see year after year that many new sounds are uploaded, and it is also incredible to see how some contributors are so dedicated and make such great efforts to upload very high quality sounds.
But what about downloads? The number of sound downloads (including packs) during 2025 was…
23,729,327 downloads!
This is ~5M more than last year, and ~2M more than two years ago. If we break this into monthly downloads, we get the following:
Number of downloads per month in 2025
Similarly to the uploads figure, northern hemisphere spring months are quite active. But there are other spikes, particularly in January (the biggest month in terms of number of downloads). It will be interesting to see why is that, if this is a recurrent pattern, and what type of sounds are downloaded in January. Maybe an idea for next year’s Freesound in numbers post series? All in all, users have downloaded more than 278M soundsand packs from Freesound!
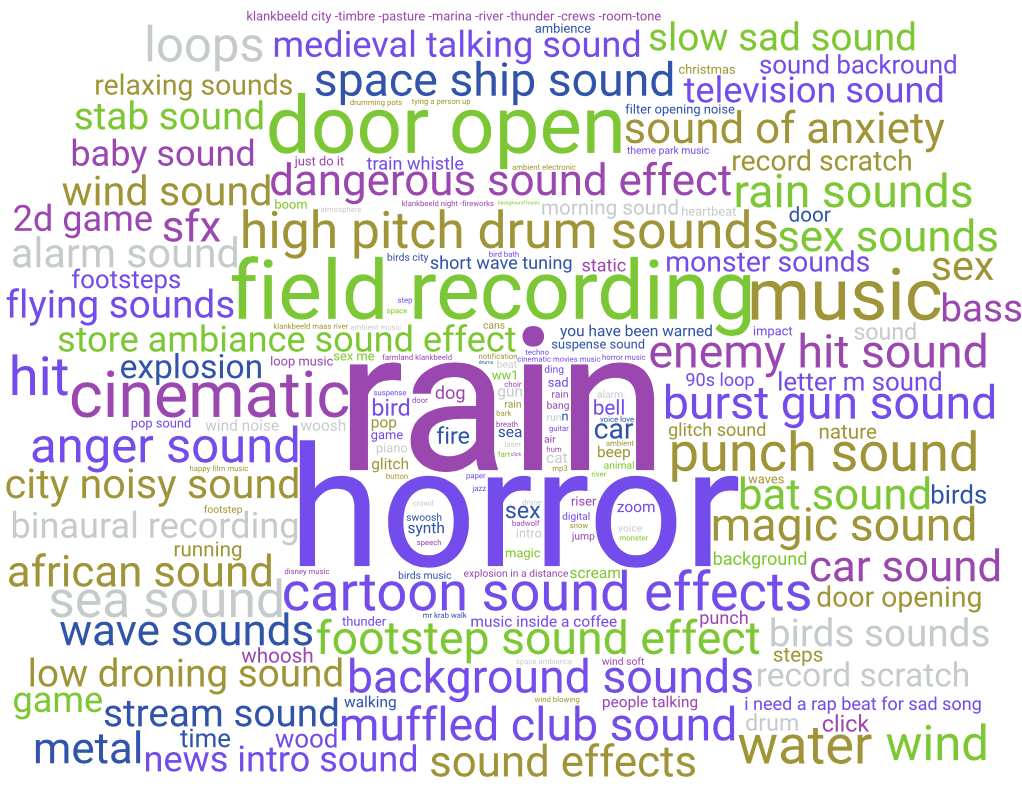
Let’s continue with the term cloud, which shows the most common query terms that have been used when searching in Freesound during 2025:
“Term cloud” of the most used search in 2025 NOTE: to improve clarity a bit, this image was updated with respect to the original one published in the post
I’ll let you dig into the term cloud to reach your conclusions but, spoilers alert, it is rather similar to previous years. Last year, for the 2024 in numbers blog post, we included a special section with more details about user queries. We recommend you to check it out if you did not do it (thanks Benno for writing that part last year!)
Now some extra general statistics: In 2025, 15.6k messages were exchanged between 2.4k unique users, 1.1k forum posts were written by 196 users, 485k sound ratings were made by 143k users, and 26.5k sound comments were written by 11k users. These numbers are quite similar to those of last year, which means that the tendency of lowering the number of sound comments but increasing the number of sound ratings is consolidated. We hypothesised in the past that this could happen due to the release of the new UI at the end of 2023, which encourages adding more sound ratings and seems to make the comments section a bit les visible. After the tendency since the release of the new UI, it looks like our hypothesis is correct.
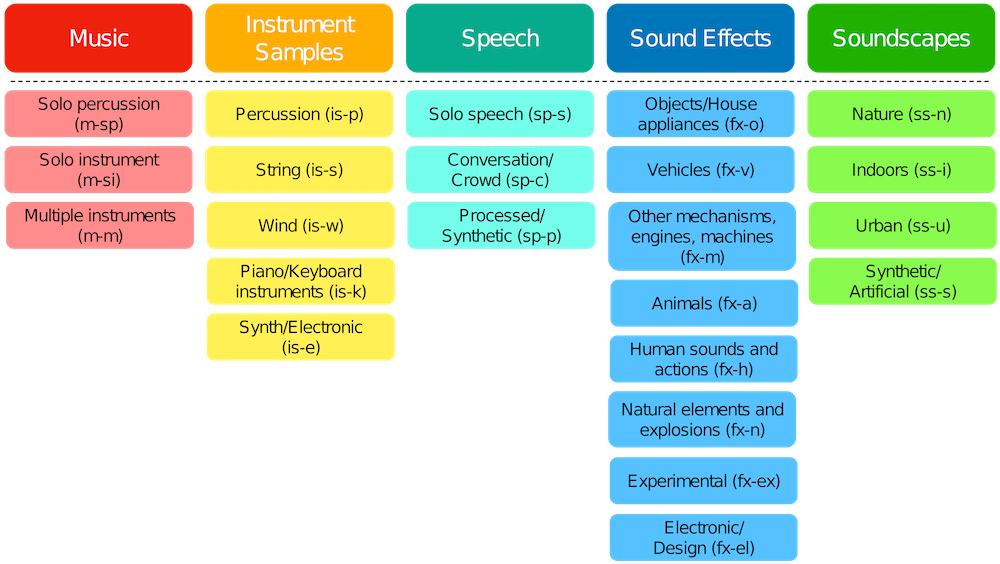
We’re now getting closer to the end of the post. But before finishing, and as it was promised, here is an extra section to deepen our understanding about what types of sounds are being shared in Freesound. And what’s the best way to do that? By classifying them :). Luckily, in April 2025, we introduced the Broad Sound Taxonomy (BST) which provides a structured way to categorize sounds across the platform. The taxonomy is designed to be simple and easy to use, and consists of 5 top-level categories and 23 second-level categories. Since April 2025, when uploading sounds, uploaders must select one of these categories and subcategories. Sounds that were uploaded before the taxonomy was introduced were automatically assigned a category by an algorithm. Here is what the taxonomy looks like:
The “Broad Sound Taxonomy”, designed by the Freesound Team
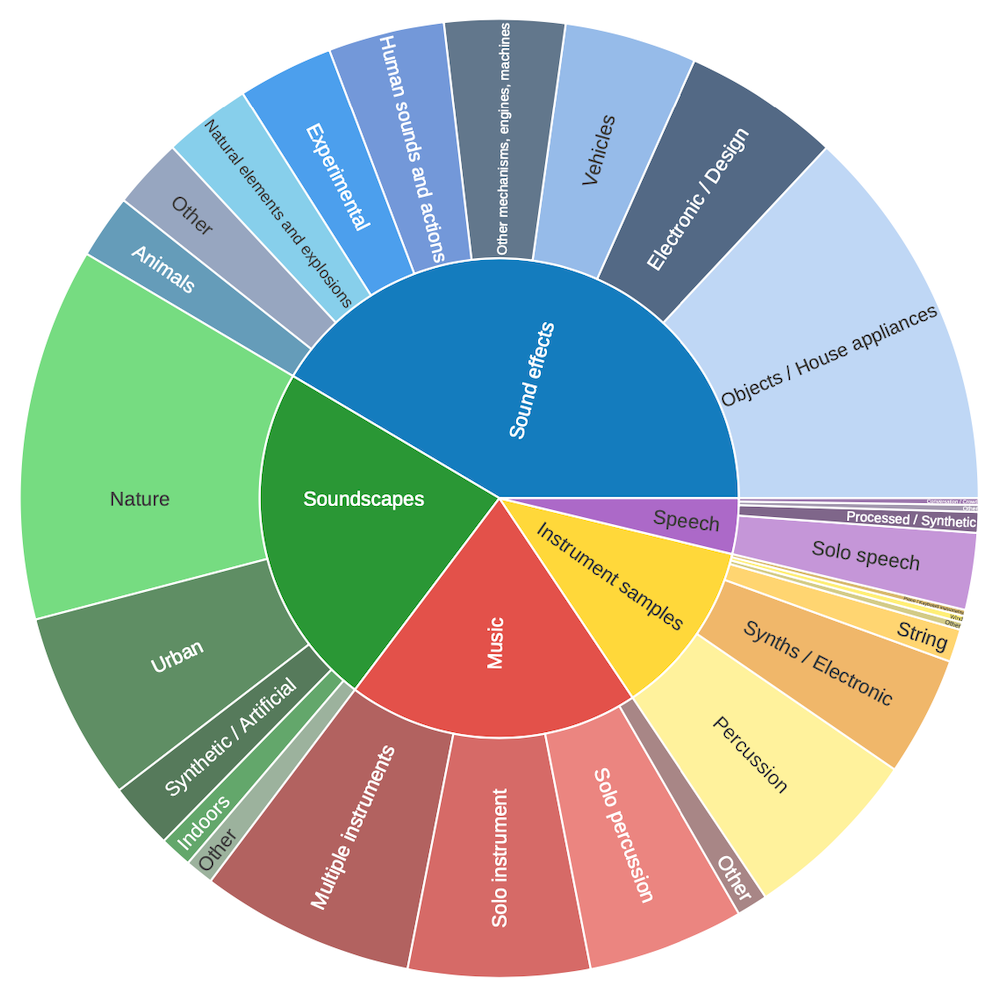
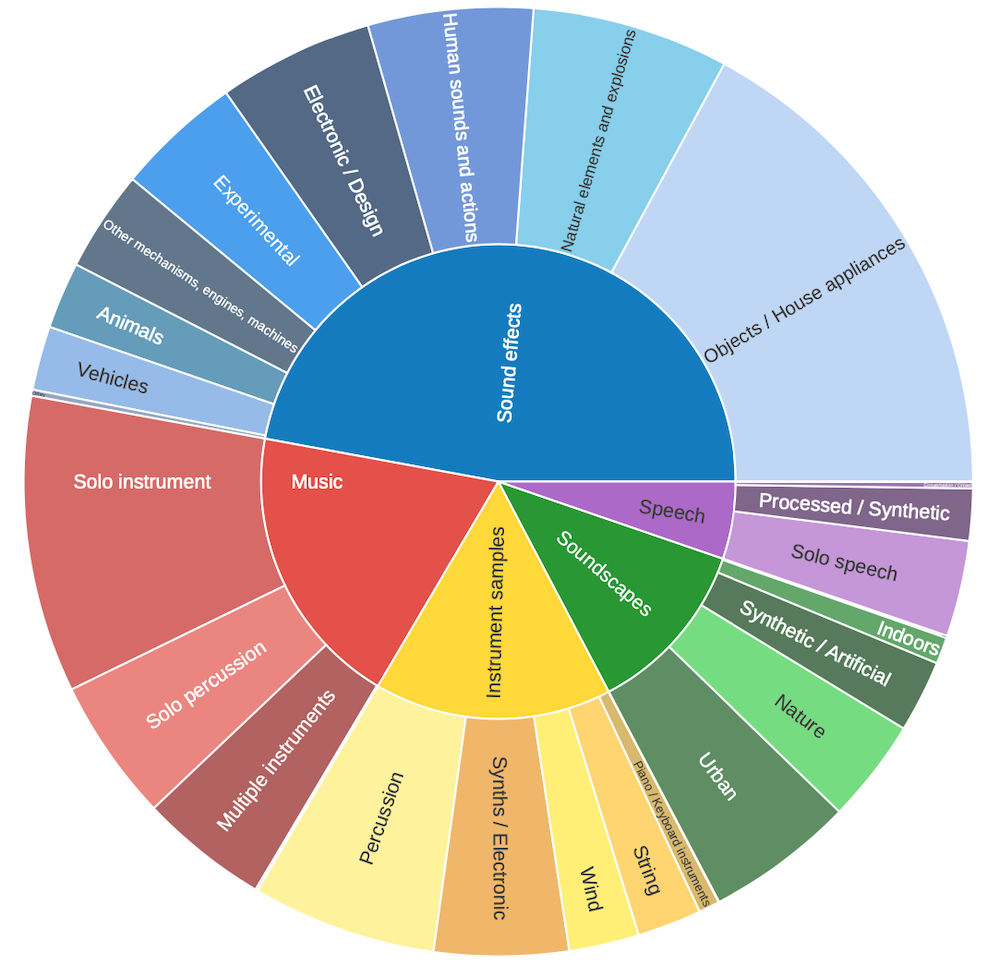
Using this taxonomy, we analysed Freesound’s uploaded content to classify sounds and identify patterns. A key finding is that uploaded sounds belong to diverse categories, emphasising the variety and heterogeneity of material contributed in Freesound. The figures below illustrate the types of sounds that were uploaded both during 2025 (figure A), and also for all time uploads (figure B). Note that automatic categorization is only used when categories have not been manually provided by sound authors.
A) Types of sounds uploaded during 2025. The inner and outer donut correspond to the two levels of the Broad Sound TaxonomyB) Types of sounds uploaded since the beginning of (Freesound) time, 20 years! The inner and outer donut correspond to the two levels of the Broad Sound Taxonomy
Comparing the two figures at the top level of BST (that is to say, considering only the 5 broad sound categories), we can see that both are quite similar. Sound effects are by far the most popular top‑level category in the taxonomy, making up the largest share of uploaded sounds. This dominance likely reflects the broad applicability of isolated sound events (e.g. footsteps, objects, engines) across many creative and practical use cases such as game audio, film post‑production, interactive media, and sound design. Some types of sounds, like music or animal recordings, might be also uploaded on other platforms, but everyday sound effects clearly remain Freesound’s focus. Among the other top-level categories, Music (excerpts, loops, melodies), Instrument samples (single notes, scales), and Soundscapes all show relatively similarly-sized distributions. The balanced mix of them shows that user interests are also heterogeneous. Speech is the least common top‑level category, which raises interesting questions about potential gaps or opportunities on Freesound. Could there be more incentives or challenges to encourage uploads in underrepresented areas like speech recordings?
Zooming in on subcategories (i.e. the second level of BST), certain types of sounds consistently stand out. Objects / House appliances are the most popular, likely because they’re easy to record in everyday life, making them a frequent upload choice for contributors. Solo instrument music (e.g. melodies, passages) is also popular, indicating that users are more likely to upload stems or isolated parts of music rather than full compositions, probably because Freesound isn’t meant for complete music pieces. This year though, there was an increase in Multiple Instrument uploads. Electronic / Design and Experimental sound effects also have a notable share, suggesting uploaders often explore synthesised or processed audio beyond natural recordings. This year we also notice an increase of Nature soundscapes, which could be likely due to individual users rather than a particular generalised new interest on it (probably due to sensingtheforest project uploads?). Lastly, Percussion are the most popular Instrument samples both in 2025 and all-time, but interestingly, there seems to be a decreased interest in uploading traditional instruments such as Winds or Piano in 2025.
There’s a lot more to discover by looking at how users navigate the taxonomy (remember that in the search page, you’ll find filters for the BST categories!). When searching, each top-level category has an Other subcategory which is used in approximately 7% of sound uploads, and indicates uploads where contributors aren’t quite sure which category to choose. That means that we might need to provide some more help to users when choosing their categories. All in all, it’s clear that Freesound is incredibly heterogeneous, and there are tons of sonic gold to discover across every type of sound. There’s a lot more to learn about the distribution of sounds in Freesound, but for now: happy uploading, and don’t forget to give a little thought to where your sounds belong and discover all corners of Freesound 🙂
Aaaaaaand that is all for this year’s post, thanks for reading and we hope you enjoy a 2026 full of sounds!
frederic and penny, on behalf of the Freesound Team
As most of you know, on the 28th of October 2025 we celebrated the Freesound Day. The Freesound Day brought together members of the Freesound community for a full day of talks, listening, and exchange around sound practices connected to Freesound. Hosted at the Campus Poblenou of Universitat Pompeu Fabra in Barcelona, and simultaneously open to online participants, the event featured a diverse program of presentations by artists, researchers, developers, and sound enthusiasts. Speakers shared personal workflows, technical insights, artistic projects, and anecdotes that highlighted the many ways Freesound has been used, shaped, and reimagined over the past 20 years. Here is the blog post where we announced the Freesound Day programme.
Today we’re making available the video recordings of the talks so anyone interested can check them out. We prepared a simple web page with a list of the talks: https://fs20.freesound.org/freesound-day/
The Freesound Day programme also included a concert with some pieces selected from the Freesound 20th Anniversary composition contest. We are planning to also publish all the pieces submitted to the composition contest in the coming weeks (even though we initially promised we’d do it by the end of 2025 😅), so stay tuned!
This year, Freesound celebrates its 20th anniversary, and Intangible Heritage has been chosen as the main theme of the celebration. Intangible heritage encompasses the ephemeral and immaterial elements that shape our world, whether rooted in human culture, natural environments, or the complex interactions between them. These sounds reflect what is fragile, ever-changing, and at risk of disappearing.
Inspired by this topic and supported by the Music Technology Group, Phonos and the City Council of Pamplona, Amaia Sagasti, former researcher and member of the Freesound team at the Music Technology Group, has carried out an initiative to create a repository of sounds from the well-known San Fermín festival.
Every year from July 6th to July 14th, San Fermín takes place, and the city of Pamplona/Iruña (200,000 inhabitants) hosts more than 1 million visitors, transforming completely. Every corner of the city fills with music and people. Beyond its iconic red and white colors and the strong smell of wine, one thing that truly stands out during San Fermín is the richness of sounds that surround the celebration, giving the festival a very unique identity.
During 2025 San Fermín festivities, microphone in hand, Amaia made numerous audio recordings across a wide variety of events, now available on the Freesound platform in a sound pack titled “San Fermín”. These recordings include a wide range of sounds from San Fermín, from the traditional songs like “Aurora a San Fermín,” “Ánimo Pues,” and “No te Vayas de Navarra” sung by crowds, to the thrilling sounds of the famous running of the bulls and the txupinazo (firework) that kicks off the celebration. The result is an open repository that lets anyone immerse themselves in the festival; not only those who have lived it firsthand, but also those who would like to experience it one day. Each sound is accompanied by descriptions in English, Spanish, and Basque, as well as an image and its location. Below are some sounds selected from the pack.
July 6, 2025 – Recording of the “Gaiteros” or bagpipers playing “Ánimo pues”, after the Txupinazo that kicks off the San Fermín festival, at the Plaza Consistorial. The crowd sings along.
July 7, 2025 – Field recording of the Santiago Choir performing “Al Glorioso San Fermín” or “La jota de tu Navarra” at “Plaza del Consejo” during the San Fermin procession.
Field recording of “aizkolarak” or log cutters, a Basque-Navarrese rural sport at “Plaza de los Fueros” in Pamplona/Iruña during the San Fermín festival.
July 7, 2025 – Recording of La Pamplonesa band playing “Jerusalén” song during the San Fermin procession.
July 11, 2025 – Field recording of the running of the bulls. The ringing of bells, followed by the sound of a firework, indicate the start of the running of the bulls at 8 a.m. The bulls’ cowbells ring as they pass by.
July 7, 2025 – “Txistus” and “Gaitas” instruments accompany the “Gigantes” and “Cabezudos” during the San Fermín procession.
July 14, 2025 – Field recording of “Riau riau”, sung during the farewell of the “peñas” at the Pamplona Bullring, on the last day of San Fermin.
July 12th, 2025 – Recording of street “txalaparta” instrument, performed by Ugarte Anaiak.
July 7, 2025 – Field recording of Cristina Ramos performing “Que hizo a San Fermín llorar” at Calle Mayor during the San Fermin procession.
July 14, 2025 – Field recording of “Pobre de Mí,” the act that concludes the 2025 San Fermin festivities. The “Pobre de mí” and “1 de Enero” songs are sung by the crowd.
The sounds of the San Fermín festival, like so many others in our lives, are part of the intangible heritage that moves us and calls us to return; heritage that deserves to be preserved. With its extensive archive, Freesound offers a digital space where these sounds can be safeguarded and reimagined.
The collaborative digital platform Freesound, created in 2005 by the Music Technology Group at Pompeu Fabra University, is celebrating its 20th anniversary, having become one of the largest databases of creative-commons licensed sounds in the world. With more than 700,000 shared recordings, Freesound has emerged as a reference for musicians, artists, researchers and creators around the world. To commemorate this anniversary, the CCCB is hosting a sound installation, curated by the Freesound team in collaboration with the artist Fito Conesa, which reflects on the concept of non-material legacies, the fragility of sound, and its value as intangible heritage.
The project installs a series of cavities and acoustic devices, which promote an intimate, deep listening, connecting us with the landscapes and the situations that make up our intangible heritage. The sounds heard in this installation have been selected by a group of artists who have been invited to explore the Freesound archive and select a playlist of “Sounds to Be Protected”: rare, unique or endangered recordings that spark a reflection on the future of our sound environment.
The installation will remain open from the 23rd to the 26th of October at Centre de Cultura Contemporània de Barcelona (CCCB). Full schedule here. The sounds selected for the installation can also be auditioned online, together with extra information for each of the playlists and the artists who curated them. You can find the digital version of the installation here: https://fs20.freesound.org/cccb/en
Decades from now, will the sound of rain be just a memory? Or a rarity? The celebration of Freesound’s 20th anniversary is also a call to preserve the acoustic memory of the world we live in.
Credits:
Installation curated by the Freesound team in collaboration with Fito Conesa
The acoustic devices were developed in collaboration with Plat Institute
The sound playlists were created by: Laura Llaneli, Alba Rihe, Roc Parés, Acoustic Heritage Collective, cantdefine.me, Cedrik Fermont, Albert Murillo, Eloïsa Matheu, Arnau Sala Saez, and Lolo & Sosaku
The Freesound Day is getting closer, and we are now able to announce the programme. For those who don’t know, the Freesound Day is an event to celebrate the 20th anniversary of Freesound, and which will feature both the Freesound team and members of the community. Participants will share their personal and professional experiences with the platform, as well as highlight various projects that have emerged around it. It will happen on the 28thofOctober2025, at the Sala Aranyó of the Campus del Poblenou of Universitat Pompeu Fabra. Even though the event will take place physically at the campus of our university in Barcelona, we are organising it so that online participation is possible.
The programme has been configured over the last months, and includes both invited talks and also the talks resulting from the Call for Talks announced in the Freesound blog some months ago. For those who can’t attend on the 28th of October, we’ll also make the talks available online later this year. The programme also includes a listening session of a selection of pieces from the Freesound 20th anniversary composition contest that was also announced earlier this year.
We hope you’ll enjoy that day and join us to celebrate Freesound!
If you are attending remotely, all you need to do is to join this Zoom meeting room: https://upf-edu.zoom.us/j/93968998691 (the room will be open 15 minutes before the start of the event)
Rutger Muller, Nikolai Gillissen, Ricky van Broekhoven (RutgerMuller)
Soundsystem for Silence – Creating Immersive Spaces with Emergent Patterns
Note: Some of the talks will happen live at the university campus, some others will be live through the Zoom meeting room, and some others will use a pre-recorded video. All of them will be streamed through the Zoom meeting room linked above.
The listening session of the Freesound 20th anniversary composition contest will feature the winning pieces of the contest, and a selection from the other submissions.
klanbeeld
River and village in 12 months
Ivan Manov
The Forgotten March of the Survakari
Beatrice Cioni
Risonanze Italiane
patnea
Echoes in the Fold
Edvina Fahlqvist and Christos Papasotiriou
Tierra Eterna
Victor Riera
Earth’s Lament
Bernardo González Castro
Relojes musicales
Christos Alexopoulos
Her Interplay
Sean Kinnear
Our Attempts (Leaves)
Diego Martinez
Sucesos irrecordables (Pouvoir tout dire)
Timothy Schmele
1972
Stefano Calvanese
MEMORIA CONDIVISA (Collective Memory)
TECNOBAITA
Free Peppino Sound
The Saucer Pilots
Waves of Memories
The listening session will NOT be streamed, but we are working on making all submitted compositions available online at a later time this year.
The contest invited sound artists, composers, and explorers from around the world to create works around the theme of Intangible Heritage, using only sounds from the Freesound archive.
We are very grateful for the enthusiastic response from the community: in total, we received 42 submissions. After a first pre-selection round carried out by members of the Freesound team in which 14 works were shortlisted, our invited jury awarded 1 First Prize, 2 Second Prizes, and 2 Honorary Mentions.
Diego Martinez“Sucesos irrecordables (Pouvoir tout dire)¨
Anniversary event
To mark this special occasion, we will host a 20th Anniversary Celebration on October 28th, 2025 at Sala Aranyó, Universitat Pompeu Fabra, Barcelona. The event will feature a public audition of the shortlisted and winning compositions, alongside talks from users of the Freesound community. The talks will be streamed to enable online participation. This will be a unique opportunity to get to know the Freesound’s community better, to hear directly from contributors, and to come together to celebrate two decades of shared sounds. We warmly invite everyone to join us in Barcelona (or remote) for this celebration! The full program of the event will be made available during the coming weeks in the Freesound blog.
Once again, we would like to thank all the participants for their contributions. The diversity of the submissions truly showcased the creative potential of Freesound’s contributors. We are working towards making all the submissions available online in the coming months. Stay tuned for more news to come!
[Guest blog post by Anna Xambó on behalf of the Sensing the Forest Team]
Sensing the Forest (StF) is a project funded by the UKRI Arts and Humanities Research Council. Our goal is to raise awareness among forest visitors, artists, scientists, and the general public about the vital connection between forests and climate change. Our central research question is:
How can the use of artistic and community science research methods help to inform and educate people about climate change?
Specifically, we are exploring what we can learn by combining artistic approaches and community science with technologies like the Internet of Things (IoT), Acoustic Ecology, and Creative Artificial Intelligence (AI) to monitor forest behaviour and raise climate awareness. Listening, understood as a way of exploring and perceiving the world, is a key research method in this project. We promote listening through artistic interventions designed to harmonise with nature.
As part of StF, we have developed two DIY, solar-powered, off-grid audio streamers led by Luigi Marino, which are installed in Alice Holt Forest (see pictures below). These streamers act as listening and recording stations, capturing the sounds of the forest. Because they are placed in public outdoor spaces, occasional human voices may be recorded.
We are building two ongoing datasets from these automatic recordings, which will span between 6 and 12 months (depending on the device) and are being uploaded to Freesound:
installation dataset (https://freesound.org/people/sensingtheforest/packs/43504/): Dendrophone is a site-specific sound installation by Peter Batchelor located in Alice Holt Forest, Surrey, UK, that transforms local environmental data into immersive sound textures. These recordings are made directly from the installation’s multichannel output and capture both its generative soundscape and the ambient natural environment.
Recordings are captured at least four times a day, timed to solar events (sunrise, solar noon, sunset, and the midpoint between sunset and sunrise). We hope these recordings will also be valuable resources for the Freesound community.
Below are some selected sound examples from the natural soundscape dataset…
Quiet, bird singing, road, airplane, early morning at about 5:30 am (4 August 2024)
Heavy rain at about 1pm (5 September 2024)
Light (granular) rain at about 1am (30 September 2024)
(Early) bird singing at about 5am (31 May 2025)
…and now some selected examples from the installation dataset.
Nice blend with natureat around 3pm (17 March 2025)
Crackles blended with light rain/wind at around 3pm (18 March 2025)
Tubular bells at around 3pm (27 March 2025)
Forest breathing with planes in the background at about 1pm (19 May 2025)
Tubular bells blended with bird songs and a plane in the background at noon (28 May 2025)
– Anna Xambó on behalf of the Sensing the Forest Team
***
Anna Xambó is a researcher and an experimental electronic music producer. Her research and practice focus on sound and music computing looking at novel approaches to collaborative, participatory, and live coding experiences. She is a Senior Lecturer in Sound and Music Computing at the Centre for Digital Music (School of Electronic Engineering and Computer Science, Queen Mary University of London) and the Principal Investigator (PI) of the UK Research and Innovation (UKRI) Arts and Humanities Research Council funded project “Sensing the Forest: Let the Forest Speak using the Internet of Things, Acoustic Ecology and Creative AI” (2023-2025).
As part of the 20th anniversary celebration program, there are two very exciting events that will take place next week in Barcelona, so be sure to check them out if you are around. The first event consists of the presentation of the piece BAR-CEL-ONA by the group Ekho, during the inaugural forum of Sónar+D music festival on the 12th of June. The second event consists of the sound installation Sound System for Silence, by the art collective Myubio, which will be open to the public from the 13th to the 21st of June at Can Framis museum, of Fundació Vila Casas. Both pieces have a particular relationship with Freesound as their authors are Freesound users and the pieces have been developed in collaboration with us. Here is more information about the two pieces:
BAR-CEL-ONA, by Ekho
On the 12th of June,Magda Polo (professor at the University of Barcelona and founder and director of the Ekho group) presents BAR-CEL-ONA at the Sónar+D 2025 festival to celebrate the twentieth anniversary of the Freesound platform. The piece, created using artificial intelligence, electronic music, and soundscapes from the open-access platform, advocates for a dissident form of listening — as formulated by Magda Polo — a listening through difference, emphasizing how we listen rather than what we listen to.
Using the sounds of the city, the Ekho group proposes a new sonic narrative, a sound portrait that goes beyond postcards, monuments, and urban clichés. “BAR,” “CEL,” and “ONA” symbolize the social spaces of streets, squares, parks, as well as the poetic horizons of the acoustic material that inhabits Barcelona, the sky, and the sea. The use of AI in the piece reveals hidden patterns that will be unveiled on the premiere day. Furthermore, as is always the case with Ekho’s works, the audience will take part.
The work not only celebrates twenty years of the Freesound platform — born, fittingly, in Barcelona — but also challenges dominant auditory hierarchies. It is an invitation to listen to what is normally marginalized, through an artistic and political practice aimed at the sensory transformation of both the individual and society.
The Ekho group, led by Magda Polo, also includes Adrien Faure, Toni Costa, and Nerea Martínez.
Soundsystem for Silence is an immersive installation inspired by the emergent patterns of nature. Using a constellation of ‘living’ sound sources, the installations sets in motion tiny fluctuations that cascade into complex shapes and movements. Aural worlds continuously emerge, evolve, disappear. Balancing between chaos and equilibria, the installation offers a new way of listening.
Celebrate 20 years of Freesound with us! We source all our sounds from this worldwide, collaborative platform – based in Barcelona. Congratulations Freesound.org!
Soundsystem for Silence is supported by Creative Industries Fund NL and the Phonos Foundation.
Myubio is the transdisciplinary sound art collective of spatial sound designer Ricky van Broekhoven, creative technologist Nikolai Gillissen and electroacoustic composer Rutger Muller.
The collective asks: is nature a composer? Can music emerge spontaneously from unpredictable mechanisms? Nature’s systems are in continuous flux. How does it transform chaos into patterns and rhythms?
Myubio reflects on this form of intelligence with installations that simulate emergence by fusing algorithms with soundscape ecology taxonomies.