Dear Freesounders,
Today we are very happy to introduce you to Freesound Datasets, a new platform that we’ve been developing during the last year to foster the re-use of Freesound content in research contexts and that will eventually help us make Freesound better and better. Curious? Check out the website at https://datasets.freesound.org/.

But what exactly is a dataset? To say it short, a dataset is a collection of items (sounds) annotated with labels chosen from a limited vocabulary of concepts. Well-curated datasets are one of the most important things that are needed to advance research in many fields, including sound and music related research.
Freesound Datasets is a platform that allows users to explore the contents of datasets made with Freesound sounds. But even more importantly, Freesound Datasets allows anyone to help make the datasets better by providing new annotations. Furthermore, it also promotes discussion about the datasets that it hosts, and allows (or better said, will allow) anyone to download different timestamped versions of them. If you’d like a more academic description about the platform, you can check out this paper we presented at the?International Society for Music Information Retrieval Conference last year: Freesound Datasets: A Platform for the Creation of Open Audio Datasets.
Using Freesound Datasets, we already started creating a first dataset which we called FSD. FSD is a big, general-purpose dataset composed of Freesound content and annotated with labels from Google?s AudioSet Ontology (a vocabulary of more than 600 sound classes). Currently, FSD is still much smaller than what we would like, but we are sure with the help of people all around the world it will get bigger and bigger. Needless to say, you are more than welcome to contribute to it (or in other words, please contribute!). All you need to do is visit the Freesound Datasets website and click on Get started with our annotation tasks! We will simply ask you to listen to some sounds and have fun 🙂 You’ll see an interface like this (you can login with your Freesound credentials):
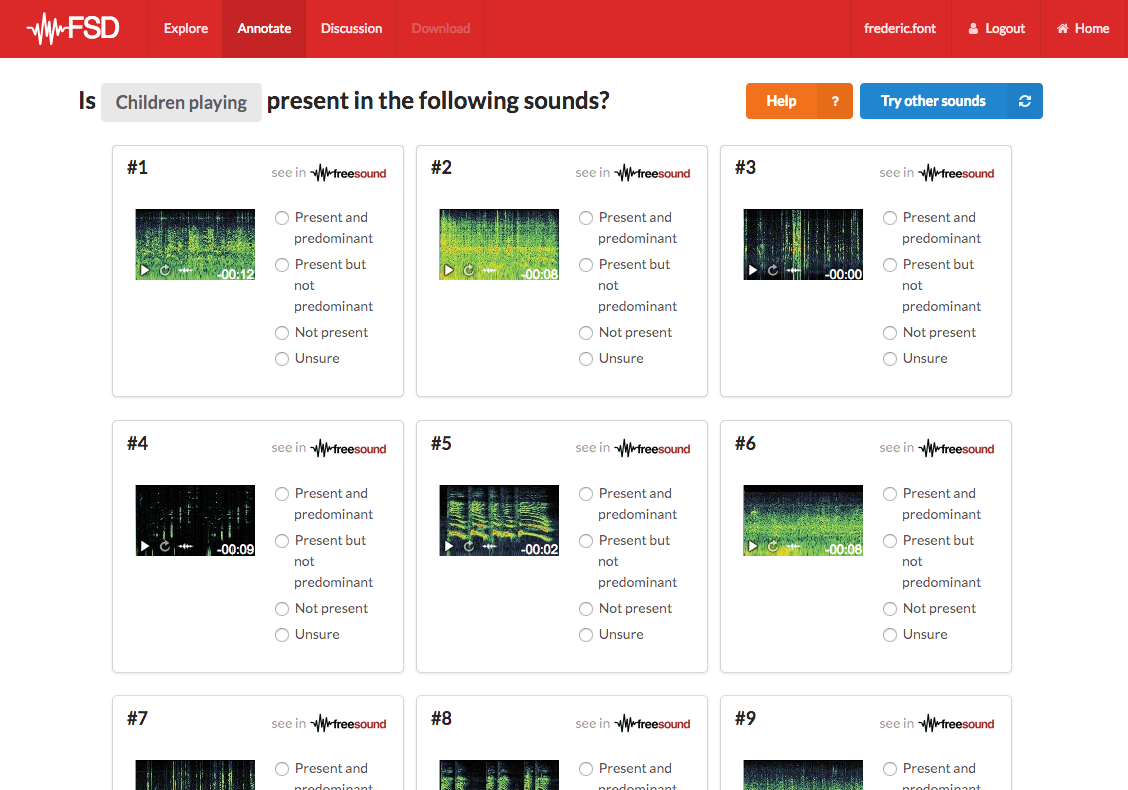
That’s really cool, isn’t it!?
Yeah that’s awesome, take me to this interface because I can’t wait any longer to start annotating!
But you know what? There is even more! We have been awarded a Google Faculty Research Award?to support the development of Freesound Datasets and FSD, and, in relation to that, have started a collaboration with some colleagues from Google’s Machine Perception Team to do research on machine listening. As the first outcome of this collaboration, we recently launched a competition in Kaggle? (see Freesound General-Purpose Audio Tagging Challenge), in which participants are challenged to build artificial intelligence algorithms able to recognize 41 diverse categories of everyday sounds. The dataset used for this competition is a small subset of FSD.
The great great great thing is that the outcomes of all these research efforts will help us improve Freesound in many ways. By training our search engine with FSD, we would, for example, be able to find search results inside sounds (for example, a fragment of a field recording with bird chirps), or be able to allow you to browse Freesound sounds using a hierarchical structure. This, and many other things that we will find out in the future 🙂
That’s it for now, thanks for reading…
the Freesound Team
AWESOME
COOL
I tried to contribute, but when I log in with my freesound account, I get “Server Error (500)”.
Sounds don’t load when I enter the page.
Tried it numerous times but always the same non-outcome ?
Hi hackerb9, this sounds like a temporary error as it seems to be working well on our side. Could you please try again?
Pax11, also seems like some sort of temporary error as it looks like is working well now. It happens that at some points if the connection is a bit slow sounds take some time to load. Sounds are in fact loaded from Freesound, so it should take the same time in Freesound and in Freesound Datasets. If you can navigate Freesound without problems, then Freesound Datasets should work for you.
It seems like a great idea. But there are some serious problems, and it seems to be off to a bad start already. I don’t want to be a Debbie Downer here, but let me raise a few concerns. And these aren’t technical site problems like the fact that I was actively voting on sounds when my submission of a page failed because my login session had expired (say what?!?), but issues at a higher level:
First of all, the categories are way too general. Consider “Arrow”, for example. Most of the candidate sounds picked are attempts to convey an arrow striking something and then wobbling. Others are an arrow being released from a bow. Many others are just a “whoosh” sound, which could be an arrow flying by, maybe, or just about anything else. But these three different interpretations of the sound of an arrow are completely, totally, and in every way different sounds. They bear almost nothing in common.
The point is, the categories only make sense in a very general, semantic way, but they are insufficient for distinguishing sounds. And tell me, what is the sound of an “Echo”? I mean, really! Just think about that one for half a second and you should realize that an echo is an attribute of the composition of potentially any other sound. These categories are pretty much worthless for machine listening, IMHO.
Secondly, the votes I’ve seen so far are quite scary. They will sometimes say something is “PP” (present and predominent) when in fact it sounds nothing at all like the category should sound, either because it is something else entirely, or a very bad attempt at creating the sound synthetically.
Perhaps, over time, this will improve. But there is an inherent problem here in that people can interpret the categories too many different ways. One person could think, “well, okay, I can imagine that could be such-and-such kind of sound, in general”, even though many of us would instead think, “oh my gosh, that is so totally fake, no real whatever would ever sound like that, and therefore this is neither representative nor useful to machine listening in any way” and vote very differently. Seriously, I’m concerned that unless this sort of ambiguity is reined in quickly, you’re going to end up with a lot of garbage on your hands that defeat the entire purpose here.
Finally, I notice some very poor generation of the “candidates”. Take for example the category “Explosion”. You’ll find everything from musical stabs to farts in there. There are a few, but only a few, very good recordings of real explosions in that collection. Most of the selections are synthetic attempts at explosions, probably as much as 80% of them. But 80% of that 80% are rather horribly done and do not bear any resemblance to real explosion sounds. Another large number of the selections are simply gunfire at best. Well, gunfire is a type of explosion, but is it really helpful for people to be thinking that way when they vote on these? Wouldn’t it be better to try to distinguish between the subtly different categories (like Explosion vs any number of other impulsive sounds, like drum hits, gun fire, artillery fire, pops, bangs, etc.)?
I went through that entire category of Explosions and only found one of my own synthetics, and it was a FakeThunder sound, not an explosion. None of my many synthetic explosions even showed up as candidates (well, I may have missed one, but I kind of doubt it). On the other hand, there were plenty of very bad synthetics with sample-rate drops and swept filter techniques that sounded horrible, and nothing like actual explosions. I also am aware that there are other real explosions sounds out there that, as far as I could tell, did not show up among the candidates.
Why is that?
I’ll stop here for now, because I’m not 100% I’ve fully understood the entire intent and mechanism. But it’s because I do believe that this could be a good idea that I am very concerned that the effort is going to be wasted due to some bad design, as if not enough thought has gone into this yet.
Hi Keith,
Thank you very much for your thoughts and thorough comments! We really appreciate people caring about the platform and definitely want to further improve it.
As a summary of my response I should say that building a good sound dataset for machine listening is a task of a very very very complex nature. We are aware of that, and during the design of the platform we had to take some decisions that we knew would not work well for all the potential audience. There are many things that we could have done better from a start, and there is surely lots of room for improvement, but we did really put a lot of thought into designing the platform and went through a number of design and implementation iterations. Really, we are taking this very seriously!
The categories included in the taxonomy of the dataset are taken form Google’s AudioSet Ontology, a hierarchical organization of all sounds in the world. Building such an ontology is again a very hard task because, as you point out, sounds can be grouped and classified in many different ways. For example, based on timbre or based on semantics. And even inside these cases there’s a lot of overlap and ambiguity. Trying to merge everything in a unified ontology is therefore very complex (and there is not a unique solution). We have adopted Google’s AudioSet Ontology because, even considering its potential errors and ambiguity, it provides a good starting point (600+ classes) and we can also contribute to improve it. I’m mentioning all of these because sometimes it does not appear as obvious that for deciding how to organize sound categories and which categories to include in the platform you need to deal with a lot of ambiguity. Even more if you’re choosing sound categories for some “general purpose” task.
Said that, we have designed two annotation tasks, one for beginners and one for experts. The task for beginners only includes a subset of categories which we considered to be easily understandable and recognizable for the average (non-expert) user. In some cases these categories tend to be very general. The task for experts includes most of the categories from the AudioSet Ontology and therefore allows for more fine-grained annotations. Still it is possible that some parts of the ontology don’t feature enough detail and annotations will remain at a more general level. We set up a discussion page for the dataset with the intention of gathering feedback and discussing about this kind of stuff, please don’t hesitate to post thoughts about specific parts of the ontology that could be improved there.
The quality of the candidates is something that varies a lot within categories. The process for choosing the candidates is automatic, based on Freesound tags (see this paper for more info), and tags are noisy (partially due to the ambiguity problems described above). If you don’t see some sounds you know from Freesound as candidates for a class it could be that 1) sounds have already been validated by other users, 2) sound was not yet uploaded to Freesound when we computed the set of candidates, 3) you did not go through all the pages, 4) sound did not met the criteria for considering it a candidate (does not have the tags we were matching with).
We also know that votes are sometimes noisy. We have implemented mechanisms to identify unreliable votes. For example, when a user validates a page of sounds we also include some sounds for which we know the answer so we can use these as an indication of the quality of the votes. If someone votes randomly, we’ll be able to detect that. Also, to consider that a candidate is “ground truth”, we look for agreement after some votes. If the candidates and the categories were better, that would most likely help improving the quality of votes as well, but we have to deal with noise and ambiguity and that’s why we implement all these mechanisms.
Finally, I would also like to comment about the idea that such noisy data is “useless” for machine listening. Big datasets always have a level of noise, and AI algorithms need to be good enough to deal with that. The data we are collecting will indeed be very useful for machine listening tasks (as an example we have launched a pilot competition in Kaggle with sounds from FSD and it’s been quite interesting so far). You are right in that better data would lead to better results, but in our view that’s something that we’ll iteratively keep on improving. For example, with the AI models that we can train now with the votes we gathered, we can improve the candidate selection system. Also by analysing the votes we can detect which categories seem to be more difficult to annotate and are more ambiguous. All this input can be very useful to further improve the platform.
I hope this answers some of your concerns 🙂
Cheers,
frederic
It does alleviate my concerns somewhat; thanks for taking the time to explain. Perhaps an area to focus on improving would be categories that describe the cause of a sound instead of the sound itself, especially where the kinds of sounds covered might be very different from each other and even be indistinguishable from a similar sound from a totally different cause. The human hearing system can often clue in to components that help distinguish one cause from another among very similar sounds, and that is worth applying machine learning to. Chewing with the mouth open creates resonances that let us know what we’re hearing, while chewing with the mouth closed can sound indistinguishable from someone walking on snow, or any number of other things. Having a single category encompass both types of sounds is confusing. Perhaps creating subcategories would be a possible solution. But I can see your point that this (any ontology, really) is an extremely difficult thing to manage.